
Clustering- Machine learning
- TECH BUDDY

- Jul 28, 2020
- 3 min read


In unsupervised learning where we don't have a target variable, we try to find patterns based on their observation, features. Based on these patterns we divide the data into groups. These groups are called clusters and the process of creating clusters is known as clustering.
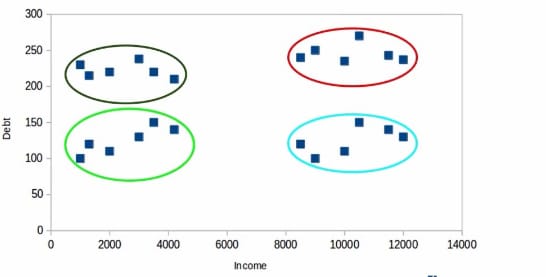
Let us understand with an example A bank wants to segments its customer base. A bank has income, age, gender, debt, credit history, and other information. A bank wants to segment into groups using these attributes. For simplicity purpose bank only uses debt and income to segment into groups. Look at the plot given below between income and debt. You can see in the plot we can segments customer into four different groups. This is how clustering is done. A bank can use these clusters for different schemes and other business purposes.

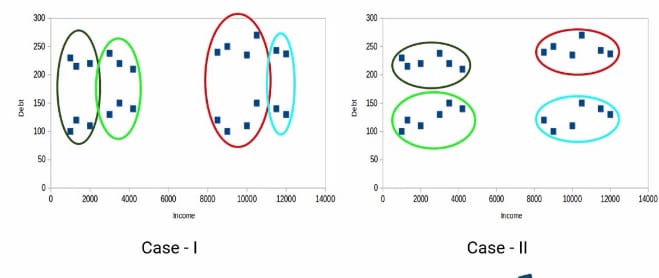
Properties of cluster
All the data points within the cluster should be similar. So that bank offers a scheme for a particular cluster. all customers can have benefit from that.
Data points from different clusters should be as different as possible. Think about the given which will give a better result. On the left side, two clusters are overlapping which will not give good results. In the left side, we can not recognize whether the datapoints is in red or green group.

Applications of clustering
Customer segmentation:- As we have discussed above how a bank wants to segment the customer base.
Document clustering:- Suppose we have multiple documents. We can group these documents by clustering based on the pattern.
Image segmentation: If we have multiple pictures, we can group them by pixel and other features through clustering.
Recommendation engines: Suppose you want to recommend songs on the basis of the song he has watched. you can do it by clustering.
Evaluation metrics for clustering
In the above example of clustering, only two attributes were considered to make a cluster. But in the real world, we have multiple features. If we consider all the features and then form a cluster, it will not be possible for us. So we can use evaluation metrics to evaluate our cluster.
Inertia:- Inertia calculates the sum of distances of all the points within a cluster from the centroid of that cluster. This distance within the clusters is known as intracluster distance. As we have studied above that all the data points within a cluster should be similar. Hence the intracluster distance should be as a minimum. We can conclude that the lesser the inertia better will be the cluster.
Dunn Index:- Inertia can only evaluate the first properties of the cluster. For evaluating the second properties of cluster we need another metric. Dunn index is an evaluation metrics to evaluate the distance between two clusters. Look at the formula of Dunn index
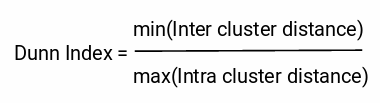
The more the value of the Dunn index, the better will be the clusters. Let us understand how it is. All the clusters should be far away from each other, so the distance between even the closest clusters should be more which will make sure that the clusters are far away from each other. The denominator should be minimum to maximize the Dunn index. Here, we are taking the maximum of intracluster distances. For a good cluster, the distance between the data point should be as minimum as possible. the distance between even the farthest clusters should be less which will make sure that the data points within the cluster are close to each other.
K-means clustering
K-means is a distance-based algorithm, where we calculate the distances to assign a point to a cluster. In K-Means, each cluster is associated with a centroid.
How k-means work?
The first step in k-means is to choose the number of clusters, k.
Randomly select the datapoint as a centroid for each cluster.
After initializing the centroids, we assign each point to the closest cluster centroid.
The next step is to calculate the centroids of newly formed clusters.
Implementation of k-means on jupyternotebook



Comments